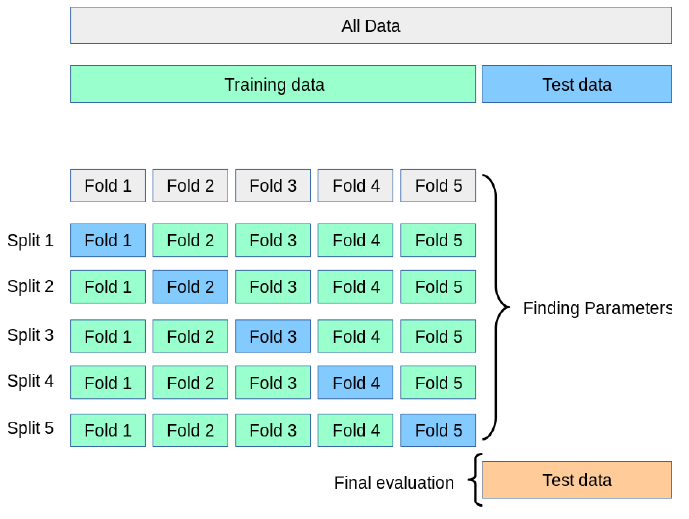
1. K-폴드 교차 검증(K-fold cross validation)은 머신러닝 모델의 일반화 성능을 더 정확하게 평가하기 위해 데이터를 K개의 동일한 크기의 폴드(덩어리)로 나누어 각 폴드가 한 번씩 검증세트가 되고 이 과정을 K번 반복하며 이를 평균내어 최종 성능을 검증하는 방법. 이 때 K값 선택은 모델 평가의 신뢰성(편향과 분산의 trade-off)과 계산 효율성 간 균형을 결정함.
2. K값에 따른 예상 결과
- 낮은 K값(ex : 5) : 훈련 데이터의 크기가 작아 모델이 전체 데이터 분포를 충분히 학습하지 못해서 편향은 높아지고 반복 횟수가 적어서 분산 및 계산 비용은 낮아짐.
- 높은 K값(ex : 10) : 훈련 데이터의 크기가 커져 모델이 데이터 분포를 정확히 학습하므로 편향은 낮이지지만 검증 세트가 작고 다양해져 분산 및 계산 비용은 높아짐.
- 극단적 K(ex : 샘플 수) : Leave-One-Out(LOO)방식 -데이터의 갯수만큼 반복 테스트하는 방법- 으로 편향 최소화가 가능하지만 계산 비용이 대단히 증가함.
3. 따라서 K값은 데이터 크기와 문제 복잡도를 고려해 5 또는 10 으로 설정하는 것이 경험적으로 최적화된 편향-분산 균형과 계산 효율성을 제공함. 그래서 대규모 데이터셋은 5, 중소규모는 10을 우선 적용해 봄.
'컴퓨터' 카테고리의 다른 글
| 부스팅은 어떤 특징을 가진 앙상블 기법인가. 토픽에서 배운 AdaBoost 이외의 부스팅 모델에는 무엇이 있는 지 각 부스팅 모델의 특징, 장단점에 대해 정리 (1) | 2025.05.31 |
|---|---|
| 결정 트리의 장점과 단점은 무엇인가 (0) | 2025.05.31 |
| 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명 (0) | 2025.05.25 |
| 손실 함수(loss function)란 무엇이며 왜 중요한가 (0) | 2025.05.25 |
| 지도 학습과 비지도 학습의 차이는 무엇인가 (0) | 2025.05.25 |



