1. 머신러닝 모델은 예측값과 실제값의 차이를 줄여 더 정확한 결과를 내는 것이 목표임.
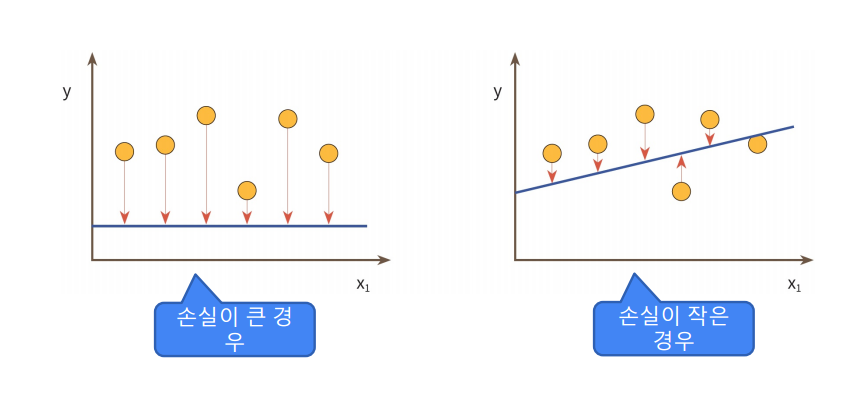
2. 손실 함수 즉 loss function은 모델의 예측값과 실제값 사이의 오차를 수치로 계산하여 모델이 값을 최소화하는 방향으로 학습되도록 유도함.
3. 따라서 손실 함수는 모델이 얼마나 잘못 예측하고 있는지 판단하고 이를 줄이는 방향으로 학습을 이끌어 최적의 성능을 달성하게 하는 핵심적 역할을 함. 대표적으로 회귀 문제에 주로 사용하는 평균제곱오차MSE(Mean Squared Error)와 분류 문제에 주로 사용하는 교차 엔트로피(Cross-Entropy)가 있음.
'컴퓨터' 카테고리의 다른 글
| K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가 (0) | 2025.05.25 |
|---|---|
| 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명 (0) | 2025.05.25 |
| 지도 학습과 비지도 학습의 차이는 무엇인가 (0) | 2025.05.25 |
| 대표적인 데이터 전처리 방법인 결측값, 중복값, 이상치 처리에 대해 설명 (0) | 2025.05.18 |
| EDA(Exploratory Data Analysis)란 무엇인가 (0) | 2025.05.18 |



