1. 부스팅이란
- 약한 학습기(weak learner)를 순차적으로 학습시키며 이전 모델이 잘못 예측한 데이터에 더 높은 가중치를 부여해 다음 모델이 그 오류를 보완하도록 만드는 앙상블 기법.
- 최종적으로 여러 학습의 예측을 결합해 강력한 예측 모델 생성
- 배깅과 달리 모델들이 순차적으로 의존하며 오답에 집중해 성능을 점진적으로 개선.
2. Adaboost 외 주요 부스팅 모델
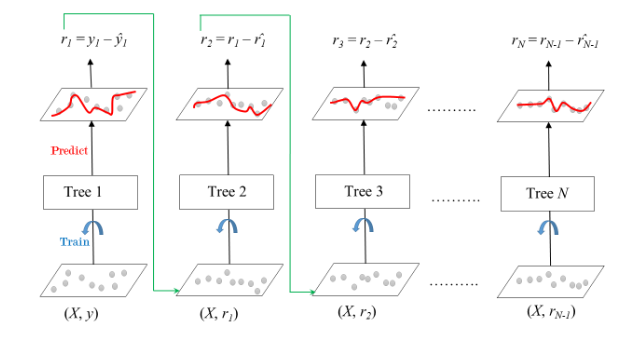
- Gradient Boosting(GBM) : 경사하강법(gradient descent)를 활용하여 이전 모델의 전차를 다음 모델이 학습함. 높은 예측 능력과 다양한 손실함수 적용이 가능하지만 학습 속도가 느리고 과적합 위험이 있음.
- XGBoost : 정규화(regularization), 가지치기, 결측치 자동처리, 병렬처리 등을 추가한 GBM의 확장판. 빠른 속도와 높은 성능, 과적합 방지 능력으로 대용량 데이터에 적합하지만, 구조가 복잡하고 하이퍼파라미터가 많으므로 학습시간이 길어질 수 있음.
- LightGBM : 리프 중심(leaf-wise) 트리 분할, 빠른 학습, 적은 메모리 사용, 범주형 변수 자동처리, 대규모 데이터에 적합하나 작은 데이터셋에서 과적합 위험과 불균형 트리 해석이 어려움.
- CatBoost : 순서형 부스팅, 대칭 트리 구조, 범주형 변수 자동 변환 및 처리, 과적합 방지, 높은 정확도, 빠른 학습이 가능하나 하이퍼파라미터 튜닝 내부 구조가 복잡하고 직관적으로 이해하기 힘듦.
3. 부스팅의 장단점
장점
- 약한 학습기를 결합해 높은 예측 성능을 보임
- 다양한 데이터에 적용 가능하며, 복잡한 데이터셋에 좋은 성능을 보임
- 과적합 방지, 정규화, 자동 결측치 처리 등 다양한 기능 추가
단점
- 이상치나 노이즈에 민감하고 오답에 집중하는 특성상 잘못된 데이터에 과도하게 적응할 수 있음
- 계산이 복잡하고 학습시간이 오래 걸릴 수 있음
- 하이퍼파라미터가 많아 튜닝이 복잡하고 작은 데이터셋에서는 과적합 위험이 커질 수 있음
따라서, 부스팅은 예측력이 뛰어나지만 노이즈에 민감하고 계산량이 많다는 단점이 있음
'컴퓨터' 카테고리의 다른 글
| 딥러닝과 머신러닝 간의 포함관계에 대해 설명 (0) | 2025.06.08 |
|---|---|
| 차원 축소 기법인 주성분 분석과 요인 분석의 차이는 무엇인가 (1) | 2025.05.31 |
| 결정 트리의 장점과 단점은 무엇인가 (0) | 2025.05.31 |
| K-폴드 교차 검증에서 K의 값을 선택할 때 고려해야 할 점은 무엇인가 (0) | 2025.05.25 |
| 모델 학습 시 발생할 수 있는 편향과 분산에 대해 설명하고, 두 개념의 관계에 대해 설명 (0) | 2025.05.25 |



